- 総合TOP
- 宇宙
- AI
- ロボット
- WEB3・メタバース
スマートフォンの音声アシスタントやChatGPTのような生成AI。これらのAI技術が私たちの言葉を理解し、返答する際に重要な役割を果たしているのが「トークン」です。
AIにとってのトークンとは、テキストを処理するための「基本単位」のことです。人間が文章を理解する際に単語や文字に分解するように、AIも言葉を細かく分割して処理します。しかし、その「分け方」が人間とは少し異なります。
本記事では、AI技術の基礎となるトークンの仕組みと役割を初心者向けに解説します。
AIが言葉を理解するための基本単位:トークンとは?
トークンとは、AIがテキストを処理する際の「ひとかたまり」のことです。本の内容を理解するために章や段落、文、単語に分けて読むように、AIも文章を小さな単位に分割して処理します。
例えば「こんにちは、元気ですか?」という文は、AIによって「こんにち」「は」「、」「元気」「です」「か」「?」などのトークンに分割されることがあります。この分割方法は、AIの種類や言語によって異なります。
言語で異なるトークンの切り方
英語のトークン化:スペースと記号が目印
英語では、単語の間にスペースがあるため、基本的には「単語」がトークンになりやすいです。例えば “How are you today?” は、 “How” 、 “are” 、 “you” 、 “today” 、 “?” のように分割されます。しかし、長い単語は更に細かく分割されることもあります。
日本語のトークン化:複雑な区切り方
日本語のような分かち書きをしない言語では、トークン化はより複雑です。「東京駅で待ち合わせ」という文は、「東京」「駅」「で」「待ち」「合わせ」のように意味のある単位で区切られることもあれば、「東」「京」「駅」「で」のように文字単位で区切られることもあります。
現代AIを支えるトークン処理技術
トークン化の背後には、さまざまな高度な技術が存在します。辞書ベースのトークン化は既存の辞書を参照して分割する方法で、機械学習ベースのトークン化はデータから自動的に最適な分割方法を学習します。
現代の生成AIの多くは、BPE(Byte Pair Encoding)と呼ばれる手法を採用しており、頻繁に現れる文字の組み合わせを学習してトークン化します。これにより、未知の単語や造語にも対応できる柔軟性を獲得しています。
AIサービスにおけるトークンの重要性
トークンは単なる技術的な概念ではなく、私たちが日常的に利用するAIサービスにも直接関わっています。
処理能力とコストを左右する単位
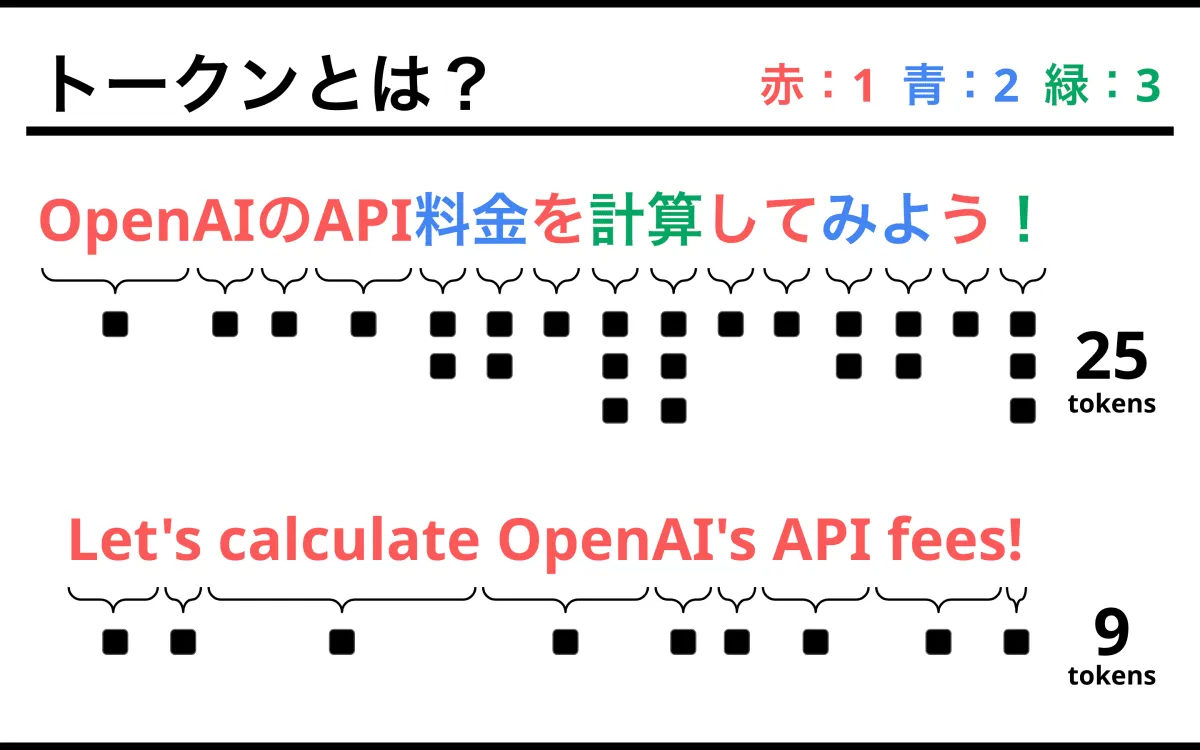
大規模言語モデル(LLM)では、処理できるトークン数が性能の指標になります。ChatGPTでは、一度に扱えるトークン数に上限があり、これが会話の長さを制限しています。また、API利用料金もトークン数に基づいて計算されることが多いため、ビジネス利用においては重要な指標となっています。
翻訳や要約の精度に影響
機械翻訳や要約では、トークン化の精度が結果に大きく影響します。日本語を英語に翻訳する際、トークン化が不適切だと「東京駅」を「東」「京駅」と誤って分割してしまい、正確な翻訳ができなくなることがあります。
AIの言語理解を支える仕組み
トークンは、AIが言葉を処理するための基本単位です。AIは分割したトークン同士の関係性やパターンを学習することで言語を理解しています。「猫」と「犬」が似た文脈で使われることや、「東京」と「日本」が関連して登場することなどを把握するのも、このトークン処理があるからです。
私たちが当たり前のように使っているAIサービスの裏側では、このようなトークン単位の緻密な処理が行われているのです。



- share
-

-

-